tensorflow-serving--模型管理
简介
准备写几个文章来记录对tensorflow代码的阅读。
本文自顶向下介绍tensorflow-serving的架构,着重介绍一下模型管理及加载机制。
整体架构
tensorflow-serving(下文简称tfserving)是对tensorflow的封装,对外提供服务接口,关系类似lucene与es。
tfserving整体可以分为三层,接口层、模型管理层、tf引擎层,如下图所示:
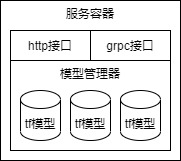
tfserving使用grpc作为服务框架,提供在线推理和模型状态查询的接口。与此同时,基于libevent实现了一个http服务,除了在线推理和模型状态查询接口外,还提供了prometheus接口用于监控。
模型管理层是serving的核心部分,负责维护模型的生命周期,重要的组件包括AspiredVersionsManager、BasicMananger、Adapter、Router、StoragePathSource等,下文将着重介绍。
tf引擎层实际是对tensorflow的封装,tfserving将其封装为Servable,通过模型名及其版本确认对应的模型,即三元组(name, version, model)。
资源交互
这部分讲一下从请求到来到推理进行里过程。
以推理为例子,调用层次如下:
- PredictionServiceImpl::Predict调用TensorflowPredictor::Predict进行预估
- TensorflowPredictor::Predict调用TensorflowPredictor::PredictWithModelSpec进行预估
- 调用ServerCore::GetServableHandle获取SavedModelBundle
- 调用ServerCore::ServableRequestFromModelSpec构建查询包
- 调用AspiredVersionsManager::GetServableHandle获得servable
- AspiredVersionsManager::GetUntypedServableHandle 调用
- BasicManager::GetUntypedServableHandle 调用
- ServingMap::GetUntypedServableHandle
- 根据ServableRequest查询HandlesMap获取对应的LoaderHarness
- LoaderHarness取出Loader指针,使用SharedPtrHandle包裹后返回。
- 调用internal::RunPredict进行预估
- 输入映射(PreProcessPrediction)
- 执行Session::Run进行预估(已经在tensorflow代码里)
- 输出打包(PostProcessPredictionResult)
- 调用ServerCore::GetServableHandle获取SavedModelBundle
TensorflowPredictor类是对推理流程的封装,保障grpc和http接口都能进行推理。
ServerCore类承接服务和模型。
ServerCore下的组件:
- AspiredVersionsManager 负责装载策略,控制装载卸载的模型版本
- BasicMananger 资源管理,提供资源管理、资源托管、资源装载卸载功能
- ServableStateMonitor 状态监视器,处理状态变化,并触发回调。
- EventBus 消息总线,连接ServableStateMonitor和AspiredVersionsManager。
- StoragePathSourceAndRouter
- ResourceTracker
模型管理
tfserving模型管理功能包括三个部分,模型配置热加载、模型版本侦测、模型加载卸载。
tfserving支持单模型和多模型两种模式,单模型通过入参控制加载的模型;多模型通过配置文件控制模型名、模型路径等。
模型配置热加载机制是针对多模型模式。
tfserving在这部分抽象了很多层,其目标是支持多种文件系统、支持多个平台(tf或者其他)、支持多个模型、支持模型的多个版本。考虑到这点就不难理解这个多层设计了。
模型配置热加载
模型配置热加载机制是创建一个定时线程,按照入参配置的时间间隔,读取指定的配置文件,然后调用ServerCore::ReloadConfig函数,重新加载模型配置。这个地方可能出现内存泄漏问题。
创建定时线程的代码在tensorflow_serving/model_servers/server.cc:343;
配置读取逻辑在tensorflow_serving/model_servers/server.cc:174;
配置应用的逻辑在tensorflow_serving/model_servers/server_core.cc:431。
配置应用逻辑里,会先校验配置内容,然后更新模型对应的配置信息(模型的路径)。
模型版本侦测
版本侦测就涉及到一套回调机制了,Source,在代码serving-1.15.0/tensorflow_serving/core/source.h:87。
上层对象将回调函数注册给下层对象,下层对象侦测到状态后,调用这个回调函数,然后将信息传递给上层对象。
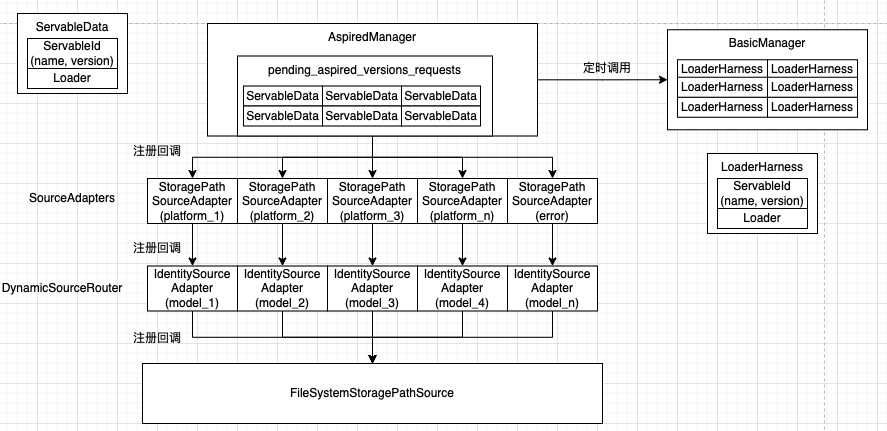
这里涉及到StoragePathSource、Router、Adapter、Manager等多个实例,他们之间的调用如下:
StoragePathSource --> Router --> Adapter --> AspiredVersionManager这里就牵扯到Source和Target关系了,即源和目标。Target提供回调函数给Source,Source按需调用该函数,回调绑定通过ConnectSourceToTarget连接。Router和Adapter既是Source又是Target。
ConnectSourcesWithFastInitialLoad中绑定了AspiredVersionManager和Adapter。
一个平台对应一个StoragePathSourceAdapter,存在SourceAdapters中。
StoragePathSource是TFS定义的对未加载模型对象的抽象, 目前实现了两种Source, 一种是StaticStoragePathSource,一种是FileSystemStoragePathSource. 前者是简单的静态的模型文件存储系统, 仅仅在启动时触发模型的加载, 没有其他动作. 后者是动态的Source, 能监测存储系统的变化并发出通知.
tfserving实现Source时将模块职责划分的很清晰, Source的职责就是监测变化, 如何处理则由Source的用户决定, 所以Source有一个接口SetAspiredVersionsCallback, 可以设置回调函数用于通知AspiredVersion的变化. Source在变化的时候就会调用设置的回调函数.
作为Source的对等对象, 系统也定义了Target, 有接口GetAspiredVersionsCallback, 用于获取处理AspiredVersions的回调接口, 然后我们就可以将Target和Source连起来了.
上述连接关系里面, Router和Adapter既是Source又是Target, AspiredVersionManager是Target. 但是Router没有实现Source接口, 而是要求在创建Router对象时直接将Adapter作为参数, 这样实现主要目的是创建一对多的关系.
系统根据所支持平台的个数(tensorflow算是一种平台)创建Adapter, 一种平台对应一个Adapter, 负责创建模型加载器Loader. 对于tensorflow平台, 对应的adapter是SavedModelBundleSourceAdapter.
Router负责根据模型名称查找对应的平台(model_config里面有指定平台名称), 从而定位到对应的Adapter.
这些连接关系是在系统启动, 或者更新model-config的时候建立的.
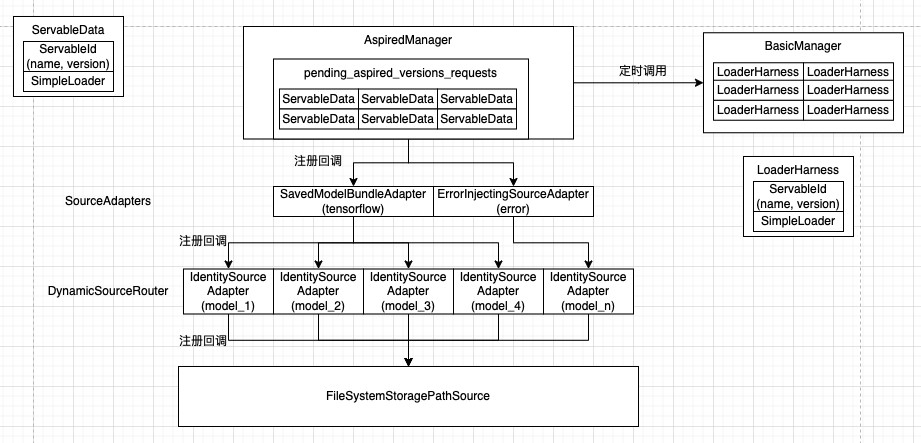
默认配置下, FileSystemStoragePathSource为Source的实例, SavedModelBundleSourceAdapter为Adapter的实例, DynamicSourceRouter为Router的实例.
FileSystemStoragePathSource有自己单独的工作线程, 周期查询文件系统, 发现每个模型的版本, 根据指定的servable_version_policy(model_config), 创建ServableData(模型名, 版本号, 路径), 传给Router
Router根据路由找到对应的adapter, 传给Adataper
Adapter将ServableData(模型名, 版本号, 路径)转换成ServableData(模型名, 版本, Loader), 传给AspiredVersionManager
AspiredVersionManager将这些信息存到pending_aspired_versions_requests_, 等待另外一个工作线程(AspiredVersionsManager_ManageState_Thread)处理
如下图左侧所示:
由于tfserving实际就 tensorflow这个平台,所以,上图实际情况如下图所示:
模型加载卸载
模型的装在卸载就需要详细介绍一下AspiredVersionsManager、BasicMananger、servable类了。
AspiredVersionsManager是总控,一端连着版本发现,一端控制模型加载,内部有个更新线程进行将待更新队列中的数据取出,进行版本更新。
BasicMananger存粹是维护模型的版本数据;servable是存粹的模型版本。
AspiredVersionsManager类
AspiredVersionsManager负责装载策略,控制装载卸载的模型版本。
成员对象包括:
- aspired_version_policy_ 装载策略
- pending_aspired_versions_requests_ 待处理资源
- manage_state_thread_ 定时任务,负责处理状态
- target_impl_ 应该是IMPL模式对象
- basic_manager_ BasicMananger类对象,资源管理
- set_num_load_threads_observer_
这个类对外(ServerCore)只提供了查询Servable的接口,用于获取模型。
这个类的对象创建之后,会启动一个后台线程去周期执行任务:
- FlushServables 清理(取消托管)无用或者状态有问题的资源
- HandlePendingAspiredVersionsRequests
- 当前资源正在卸载中的,跳过本次处理
- 之前出现镜像版本不在新增版本中 (应该是该版本本地数据被删除,但是还没被卸载)
- 这次该版本出现在新增版本中
- 处理选中版本逻辑
- 获取新版本列表
- 获取当前版本列表
- 镜像版本不在新版本中,进行标记(本地数据已经被删除)
- 获取差集(新版本 - 当前版本)进行托管
- 当前资源正在卸载中的,跳过本次处理
- InvokePolicyAndExecuteAction 筛选一个操作(模型装载或卸载),并执行
- 获取每个模型的每个版本的镜像状态
- 针对每个模型,使用装载策略器筛选一个“操作”(至多一个)
- 针对所有模型的“操作”,筛选(优先卸载)一个执行
调用basic_manager的装载或者卸载接口进行操作。
pending_aspired_versions_requests_存储等待处理队列,调用关系有点绕:
- AspiredVersionsManagerTargetImpl::SetAspiredVersions
- AspiredVersionsManager::EnqueueAspiredVersionsRequest
- 添加pending_aspired_versions_requests_
装载策略:
- AvailabilityPreservingPolicy
- ResourcePreservingPolicy
BasicMananger类
BasicManager,负责资源管理,提供资源获取、资源托管、资源装载、资源卸载,主要结构如下:
- servable_event_bus_ 状态消息分发
- managed_map_ 已托管的资源表,multimap<模型名, LoaderHarness_Ptr>
- serving_map_ 就绪的模型表类,类型是ServingMap,里面也是multimap结构
- load_executor_和unload_executor_是装载、卸载的线程池
BasicManager提供的接口:
- ManageServable 托管资源
- 从ServableData对象中取出Loader和ServableId,装入LoaderHarness
- 发布消息<ServableId, kStart>
- 加入managed_map_中进行管理
- LoadServable 装载资源,资源必须被托管
- 构建LoadOrUnloadRequest对象
- 获取LoaderHarness对象
- 检查LoaderHarness对象是否已经装载
- 调度进行装载,配置了线程池就用线程池
- 获取LoaderHarness对象
- 预先分配资源
- 修改资源状态为kLoadApproved
- 发布事件kLoading
- 调度LoaderHarness的Load函数进行装载
- 更新ServingMap数据
- 发布事件kAvailable
- UnloadServable 卸载资源
- 构建LoadOrUnloadRequest对象
- 获取LoaderHarness对象
- 检查LoaderHarness对象是否已经卸载
- 调度进行卸载,配置了线程池就用线程池
- 获取LoaderHarness对象
- 修改资源状态为kQuiescing
- 发布事件kUnloading
- 更新ServingMap数据
- 修改新状态为kQuiesced
- 调度LoaderHarness的Unload函数进行卸载
- 发布事件kEnd
- StopManagingServable 取消托管资源
- 从managed_map_中删除资源
- GetUntypedServableHandle 获取资源
- 从serving_map_中获取资源
- 查询unordered_multimap里查询LoaderHarness对象
- LoaderHarness中取出ServableId和Loader,装入SharedPtrHandle
- 从serving_map_中获取资源
- 其他查询接就不介绍了
servable类
一个servable对应一个模型的一个版本,这里涉及到多个类:
- SavedModelBundle 实际模型
- Session 对象
- meta_graph_def graph申明
- ServableHandle 类似智能指针,但是不管理内存
- UntypedServableHandle 基类,定义了获取servable的句柄。
- SharedPtrHandle UntypedServableHandle的实现,从Loader中获取servable对象。
- ServableRequest 用来查询manager获得指定版本模型的阐述对象(Params)
他们的关系是: manager中存了SharedPtrHandle对象,通过ServableRequest查询对应的SharedPtrHandle;使用时将获取的使用ServableHandle将获取的SharedPtrHandle对象中的Loader维护的SavedModelBundle取出。
更新流程
AspiredVersionsManager对象从队列中取到版本,跟自身的版本进行比较,得到需要更新的版本数据。
AspiredVersionsManager调用BasicMananger::LoadServable,装载模型。
BasicMananger进行一连串调用之后,LoaderHarness、SimpleLoader等之后,就到tensorflow里的代码了。