tensorflow模型数据解析
简介
本文将介绍一下tensorflow的saved model数据的结构。
模型文件
tensorflow的saved model的目录结构如下:
- saved_model.pb 模型描述文件,pb二进制; 也可以是pbtxt后缀的文本文件
- variables 模型参数数据目录
- variables.index 模型索引文件
- variables.data-00000-of-00001 模型数据文件
- assets.extra
- tf_serving_warmup_requests 预热请求包,pb二进制文件
模型加载流程
参考上一篇文章中模型加载流程,模型加载时会调用LoadSavedModel函数用于加载模型。
这个函数调用LoadSavedModelInternal进行实际的加载操作:
- ReadMetaGraphDefFromSavedModel
- LoadMetaGraphIntoSession
- GetAssetFileDefs
- RunRestore
其中RunRestore函数中加载了参数数据,具体操作是执行该模型图中bundle->meta_graph_def.saver_def().restore_op_name()算子。
以half_plus_two_pbtxt为例,文件在tensorflow-1.15.0/tensorflow/cc/saved_model/testdata/half_plus_two_pbtxt/00000123/saved_model.pbtxt。
图中saver_def内容如下:
saver_def {
filename_tensor_name: "save/Const:0"
save_tensor_name: "save/Identity:0"
restore_op_name: "save/restore_all"
max_to_keep: 5
sharded: true
keep_checkpoint_every_n_hours: 10000.0
version: V2
}加载时需要执行”save/restore_all”算子, 由于依赖关系,实际上需要执行多个算子。
使用netron工具打开图描述,可以看到如下:
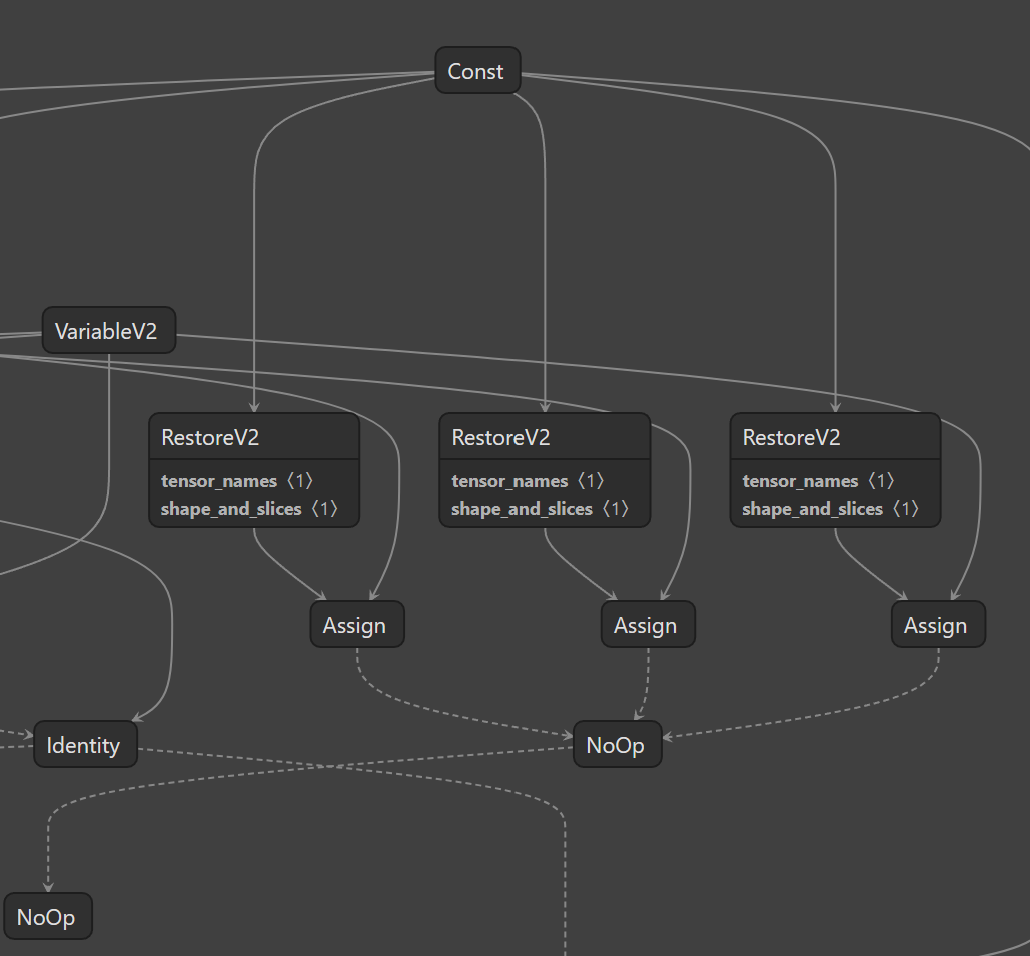
它本身是个NoOp,主要依赖了RestoreV2算子和Assign算子。其中,RestoreV2算子实际加载了数据。
RestoreV2算子代码在tensorflow-1.15.0/tensorflow/core/kernels/save_restore_v2_ops.cc中。
整个流程包括:
- 查询index文件的index段, 获取data块的信息
- 查询index文件的data段中的块,获得数据段信息
- 根据数据段信息,从data文件中截取数据.
整个调用栈:
- RestoreV2::Compute 数据加载
- ValidateInputs 校验
- RestoreTensorsV2 加载数据
- 校验tensor_name的类型
- 遍历拆分队列(维度多的多线程跑,维度小的单线程跑)
- RestoreOp::run 加载一个tensor name
- BundleReader::LookupTensorShape 获取形状
- BundleReader::Lookup 没设置shape_and_slice
- BundleReader::LookupSlice 有设置 shape_and_slice
RestoreOp::run运行时会创建BunleReader对象,这里涉及到一个初始化过程:
- 解析footer
- 加载index文件的index段
- 读取header数据
header的结构为BundleHeaderProto, 定义如下:
message BundleHeaderProto {
// Number of data files in the bundle.
int32 num_shards = 1;
// An enum indicating the endianness of the platform that produced this
// bundle. A bundle can only be read by a platform with matching endianness.
// Defaults to LITTLE, as most modern platforms are little-endian.
//
// Affects the binary tensor data bytes only, not the metadata in protobufs.
enum Endianness {
LITTLE = 0;
BIG = 1;
}
Endianness endianness = 2;
// Versioning of the tensor bundle format.
VersionDef version = 3;
}header数据的key为空字符串,header中保存了分片数量,即data文件的数量。
BundleReader::Lookup的逻辑如下:
- BundleReader::GetBundleEntryProto 获取pb结构
- BundleReader::Seek
- TwoLevelIterator::Seek
- index_iter_->Seek 在index块中找到target
- TwoLevelIterator::InitDataBlock 设置data_iter(没有就创建)
- data_iter_->Seek 在data块中查找target
- TwoLevelIterator::SkipEmptyDataBlocksForward
- ParseEntryProto 数据解析成BundleEntryProto结构
- TwoLevelIterator::Seek
- BundleReader::Seek
- GetValue 根据BundleEntryProto结构中的信息,在data文件中读取数据
- GetSliceValue 分段读取数据
其中GetValue和GetSliceValue是两选一。
如果在调用BundleReader::GetBundleEntryProto拿到的BundleEntryProto结构中有slices结构,则表示数据进行分段了,
需要拼接一组新的key,然后依次调用BundleReader::GetBundleEntryProto和GetValue获取数据.
// Describes the metadata related to a checkpointed tensor.
message BundleEntryProto {
// The tensor dtype and shape.
DataType dtype = 1;
TensorShapeProto shape = 2;
// The binary content of the tensor lies in:
// File "shard_id": bytes [offset, offset + size).
int32 shard_id = 3;
int64 offset = 4;
int64 size = 5;
// The CRC32C checksum of the tensor bytes.
fixed32 crc32c = 6;
// Iff present, this entry represents a partitioned tensor. The previous
// fields are interpreted as follows:
//
// "dtype", "shape": describe the full tensor.
// "shard_id", "offset", "size", "crc32c": all IGNORED.
// These information for each slice can be looked up in their own
// BundleEntryProto, keyed by each "slice_name".
repeated TensorSliceProto slices = 7;
}当slices为非空时,表示当前数据采用了分段的方式,就会调用GetSliceValue。
这个函数中会根据tensor_name和slices数据,生成一个key列表,然后再走一边BundleReader::GetBundleEntryProto和
GetValue获取实际的数据。
模型数据结构
如果看过leveldb源码,就会发现,这两个代码的分段逻辑出奇的相似。
index文件分为index段、data段和footer段三部分。
footer段为48字节,末尾8个字节是magic字段用于校验,前面40字节中存储了四个vint64的数据,分别是:
- meta_index_handle
- offset
- size
- index_handle
- offset
- size
其中index_index_handle记录index段的位置。
index段包括三个部分,数据部分(index_handle.size大小)、压缩flags(1字节)、校验位(4字节)。
数据部分包括entry结构数组、偏移数组、entry数量(4字节),其中entry数组和偏移数组长度相同。
entry结构数组中的entry是按照entry.key进行排序的,也就是一个有序数组。
根据key进行查询时,先二分在偏移数组中查找,比较阶段会读取entry中的key进行比较。
找到index后,在entry中线性搜索,确认是否真是存在。
entry中包含五个部分:
- shared 固定为0,
- noshared key的长度
- value_length value的长度
- key key数据
- value value数据
shared字段存在的原因应该是跟leveldb结构保持一致,leveldb中块中的key分为前缀和后缀。
shared字段恒为0,表示并没有使用这个前缀后缀机制。
data段的数据结构跟index段数据结构基本一致。
差别是index段中的value存两个vint64字段,分别表示key所在的data段的偏移和长度。
也就是查询时,先在index段中找到data段的偏移和长度,然后在众多data段中再次查找,找到对应的value。
data段中的value是pb二进制文件,前面已经介绍过。
index文件的结构如下:

data文件结构相对简单,data文件的数量记录在header中,即key为空字符串的value里。
index文件里查询出的BundleEntryProto结构,可以定位到(shared_id, offset, size)三元组,直接读取即可。